У чому я бачу цінність протоколів ідентифікації ТІМу
Спостерігаємо результат. Якщо інформації достатньо за кожною функцією, якщо теорія була правильна, то:
- Усі функції поділяться на дві частини: половина маловимірні (2 рац і 2 іррац), половина багатовимірні (2 рац і 2 іррац).
- Усі функції поділяться на дві частини: половина вітальні, половина ментальні. При цьому кожен макроаспект розділиться (якщо біла функція в менталі, то чорна - у віталі).
- Усі функції поділяться на дві частини за знаками (білі з одним знаком, чорні з іншим).
Погодьтеся, доволі складна комбінація, яка має скластися в результаті.
Будь-яка людина може перевірити аналіз ще раз, оскільки вся інформація про методику анализу і також протоколи є у відкритому доступі на сайті ШСС.
У протоколах спеціально введена колірна індикація. Якщо складно заглиблюватися в аналіз тексту, то можна просто переглянути розподіл кольорів (за розмірністю функцій).
Крім того можна переглянути кожен протокол через програму «Інформаційний аналіз» (ІА), в якій є можливість робити вибірку за кожним параметром, а також побачити систему переведення управління. Це теж показово.
Наприклад:
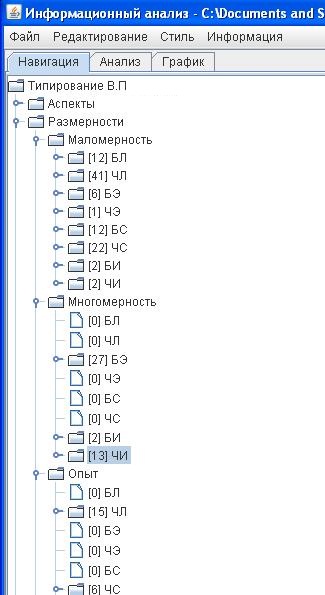
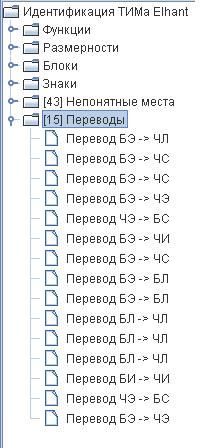
Ці ж закономірності розподілу можна простежити в підсумкових таблицях, які генерує програма ІА в протоколі:
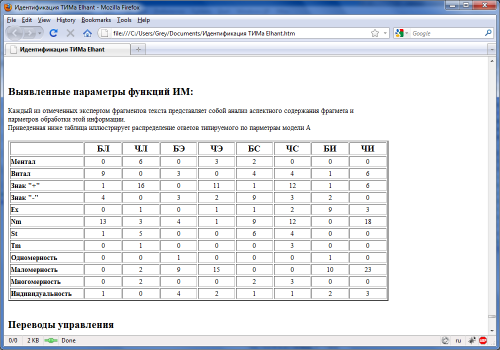

Хтось вважає, що такої кількості протоколів недостатньо для певних висновків. Потрібні тисячі? Колись їх буде стільки. Це тільки початок. Але це задокументований факт наявності певної структури опрацювання інформації, яка відповідає теоретичній моделі А.
Егліт І.М.